Robots.txt-Datei: Was sie ist, wie man sie einrichtet und überprüft
Eine robots.txt-Datei ist ein Textdokument, das sich im Stammverzeichnis einer Website befindet und Informationen für Suchmaschinen-Crawler darüber enthält, welche URLs – die Seiten, Dateien, Ordner usw. enthalten – gecrawlt werden sollen und welche nicht. Das Vorhandensein dieser Datei ist für den Betrieb der Website nicht zwingend erforderlich, aber gleichzeitig ist ihre korrekte Einrichtung das Herzstück der Suchmaschinenoptimierung.
Die Entscheidung, robots.txt zu verwenden, wurde bereits 1994 als Teil des Robot Exclusion Standards getroffen. Laut Google Help Center besteht der Hauptzweck der Datei nicht darin, die Anzeige von Webseiten in den Suchergebnissen zu verhindern, sondern die Anzahl der von Robotern an Websites gestellten Anfragen zu begrenzen und die Serverlast zu verringern.
Im Allgemeinen sollte der Inhalt der Datei robots.txt als Empfehlung für Suchcrawler betrachtet werden, die die Regeln für das Crawlen von Websites festlegt. Um auf den Inhalt der robots.txt-Datei einer beliebigen Website zuzugreifen, musst Du lediglich “/robots.txt” nach dem Domainnamen in den Browser eingeben.
Wofür wird robots.txt verwendet?
Die Hauptfunktion des Dokuments besteht darin, das Scannen von Seiten und Ressourcendateien zu verhindern, damit das Crawl-Budget effizienter eingesetzt werden kann. In den allermeisten Fällen verbirgt die robots.txt-Datei Informationen, die den Besuchern der Website keinen Nutzen bringen und sich nicht auf die SERP-Rankings auswirken.
Hinweis: Das Crawl-Budget ist die Anzahl der Webseiten, die ein Suchroboter crawlen kann. Um es sparsamer zu nutzen, sollten Suchroboter nur auf die wichtigsten Inhalte von Webseiten geleitet werden und der Zugriff auf nicht hilfreiche Informationen gesperrt werden.
Welche Seiten und Dateien werden normalerweise über robots.txt gesperrt?
1. Seiten mit personenbezogenen Daten.
Zu den personenbezogenen Daten können Namen und Telefonnummern gehören, die die Besucher bei der Registrierung angeben, persönliche Dashboards und Profilseiten, Zahlungskartennummern. Aus Sicherheitsgründen sollte der Zugang zu solchen Informationen zusätzlich mit einem Passwort geschützt werden.
2. Hilfsseiten, die nur nach bestimmten Benutzeraktionen erscheinen.
Zu solchen Aktionen gehören typischerweise Nachrichten, die Kunden nach erfolgreichem Abschluss einer Bestellung erhalten, Kundenformulare, Autorisierungs- oder Passwortwiederherstellungsseiten.
3. Admin-Dashboard und Systemdateien.
Interne Dateien und Servicedateien, mit denen Website-Administratoren oder Webmaster interagieren.
4. Seiten für die Suche und die Sortierung nach Kategorien.
Seiten, die angezeigt werden, nachdem ein Website-Besucher eine Suchanfrage in das Suchfeld der Website eingegeben hat, sind in der Regel für die Crawler von Suchmaschinen gesperrt. Das Gleiche gilt für die Ergebnisse, die Nutzer erhalten, wenn sie Produkte nach Preis, Bewertung oder anderen Kriterien sortieren. Aggregator-Websites können eine Ausnahme bilden.
5. Seiten filtern.
Ergebnisse, die mit einem angewandten Filter (Größe, Farbe, Hersteller usw.) angezeigt werden, sind separate Seiten und können als doppelte Inhalte betrachtet werden. Als Faustregel gilt, dass SEO-Experten auch verhindern, dass sie gecrawlt werden, außer in Fällen, in denen sie Traffic für Marken-Keywords oder andere Zielanfragen erzeugen.
6. Dateien mit einem bestimmten Format.
Zu diesen Dateien können Fotos, Videos, PDF-Dokumente und JS-Dateien gehören. Mit Hilfe von robots.txt kannst Du das Scannen von einzelnen oder erweiterungsspezifischen Dateien einschränken.
Wie wird eine robots.txt-Datei erstellt und wo wird sie abgelegt?
Tools für die Einrichtung von robots.txt
Da das Dokument eine .txt-Erweiterung hat, ist jeder Texteditor geeignet, der die UTF-8-Kodierung unterstützt. Die einfachste Option ist Notepad (Windows) oder TextEdit (Mac).
Du kannst auch ein robots.txt-Generator-Tool verwenden, das eine robots.txt-Datei auf der Grundlage der angegebenen Informationen erstellt.
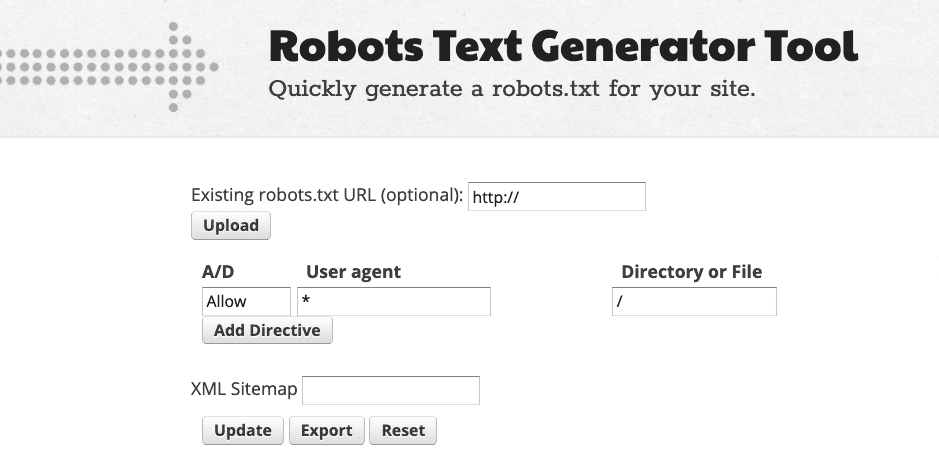
Titel und Größe des Dokuments
Der Name der robots.txt-Datei sollte genau so aussehen, ohne dass Großbuchstaben verwendet werden. Gemäß den Google-Richtlinien beträgt die zulässige Dokumentgröße 500 KiB. Eine Überschreitung dieser Grenze kann dazu führen, dass der Suchroboter das Dokument nur teilweise verarbeitet, die Website überhaupt nicht crawlt oder umgekehrt den Inhalt einer Website vollständig scannt.
Wo soll die Datei abgelegt werden?
Das Dokument muss sich im Stammverzeichnis des Website-Hosts befinden und kann per FTP abgerufen werden. Bevor Du Änderungen vornimmst, solltest Du die robots.txt-Datei in ihrer ursprünglichen Form herunterladen.
robots.txt-Syntax und -Richtlinien
Sehen wir uns nun die Syntax einer robots.txt-Datei genauer an, die aus Direktiven (Regeln), Parametern (Seiten, Dateien, Verzeichnisse) und Sonderzeichen besteht, sowie die Funktionen, die sie erfüllen.
Allgemeine Anforderungen an den Dateiinhalt
1. Jede Richtlinie muss in einer neuen Zeile beginnen und nach dem Prinzip: eine Zeile = eine Richtlinie + ein Parameter gebildet werden.
| Falsch | User-agent: * Disallow: /Ordner-1/ Disallow: /Ordner-2/ |
| Richtig | User-agent: *
Disallow: /Ordner-1/ Disallow: /Ordner-2/ |
2. Dateinamen, die andere Alphabete als das lateinische verwenden, sollten mit dem Punycode-Konverter umgewandelt werden.
| Falsch | User-agent: Disallow: /φάκελος-με-επαφές/ |
| Richtig | Disallow: /xn--v8bgtvbb4blm8as0bi7an/ |
3. Bei der Syntax der Parameter musst Du dich an das entsprechende Register halten. Wenn ein Ordnername mit einem Großbuchstaben beginnt, verwirrt es den Roboter, wenn er mit einem Kleinbuchstaben benannt wird. Und andersherum.
| Falsch | User-agent: Disallow: /Ordner/ |
| Richtig | Disallow: /Ordner/ |
4. Die Verwendung eines Leerzeichens am Zeilenanfang, von Anführungszeichen oder Semikolons für Direktiven ist streng verboten.
| Falsch | User-agent: Disallow: /ordner-1/;
Disallow: /”Ordner-2″/ |
| Richtig | Disallow: /Ordner-1/
Disallow: /Ordner-2/ |
5. Eine leere oder nicht zugängliche robots.txt-Datei kann von Suchmaschinen als Erlaubnis zum Crawlen der gesamten Website aufgefasst werden. Um erfolgreich verarbeitet zu werden, muss die robots.txt-Datei den HTTP-Antwortstatuscode 200 OK zurückgeben.
Symbole der Datei robots.txt
Sehen wir uns die wichtigsten Symbole in der Datei an und finden wir heraus, was jedes einzelne bedeutet.
Der Schrägstrich (/) wird nach dem Befehl und vor dem Namen der Datei oder des Verzeichnisses (Ordner, Abschnitt) eingefügt. Wenn Du das gesamte Verzeichnis schließen willst, musst Du ein weiteres “/” hinter den Namen setzen.Disallow: /search/
Disallow: /standarts.pdf
Das Sternchen (*) zeigt an, dass die robots.txt-Datei für alle Suchmaschinenroboter gilt, die die Website besuchen.
User-agent: * bedeutet, dass die Regeln und Bedingungen für alle Robots gelten.
Disallow: /*videos/ bedeutet, dass alle Website-Links, die /videos/ enthalten, nicht gecrawlt werden.
Das Dollarzeichen ($) ist eine Einschränkung in Form eines Sternchens, die für URL-Adressen von Websites gilt. So ist beispielsweise der Inhalt einer Website oder einer einzelnen Datei nicht zugänglich, aber Links, die den angegebenen Namen enthalten, sind verfügbar.
Disallow: /*Ordner-1/$
Die Raute (#) markiert jeden nachfolgenden Text als Kommentar und bedeutet, dass er von Suchrobotern nicht berücksichtigt wird.
#Suchroboter werden diese Informationen nicht sehen.
robots.txt-Datei-Richtlinien
- User-agent
Der User-Agent ist eine obligatorische Direktive, die den Suchroboter definiert, für den die definierten Regeln gelten. Wenn es mehrere Bots gibt, beginnt jede Regelgruppe mit diesem Befehl.
Beispiel
User-agent: * bedeutet, dass die Anweisungen für alle vorhandenen Robots gelten.
User-agent: Googlebot bedeutet, dass die Datei für den Google-Roboter bestimmt ist.
User-agent: Bing bedeutet, dass die Datei für den Bing-Roboter bestimmt ist.
User-agent: Yahoo! bedeutet, dass die Datei für den Yahoo! Robot bestimmt ist.
- Disallow
Disallow ist ein Schlüsselbefehl, der Suchmaschinen-Bots anweist, eine Seite, eine Datei oder einen Ordner nicht zu durchsuchen. Die Namen der Dateien und Ordner, auf die Sie den Zugriff beschränken möchten, werden nach dem Symbol “/” angegeben.
Beispiel 1. Angeben verschiedener Parameter nach Disallow.
disallow: /link to page verbietet den Zugriff auf eine bestimmte URL.
disallow: /Ordnername/ schließt den Zugriff auf den Ordner.
disallow: /image/ schließt den Zugriff auf das Bild.
disallow: /Das Fehlen jeglicher Anweisungen nach dem “/”-Symbol zeigt an, dass die Website vollständig vom Scannen abgeschottet ist, was bei der Entwicklung von Websites sehr nützlich sein kann.
Beispiel 2. Deaktivieren des Scannens aller .PDF-Dateien auf der Website.
User-agent: Googlebot
Disallow: /*.pdf
- Allow
In der Datei robots.txt erfüllt Allow die gegenteilige Funktion von Disallow, indem es den Zugriff auf Website-Inhalte erlaubt. Beide Befehle werden in der Regel zusammen verwendet, beispielsweise wenn Du den Zugriff auf eine bestimmte Information wie ein Foto in einem versteckten Mediendateiverzeichnis freigeben musst.
Beispiel. Scannen eines Bildes in einem geschlossenen Album mit “Zulassen”.
Geben Sie das Verzeichnis Allow, die URL des Bildes und in einer weiteren Zeile Disallow zusammen mit dem Namen des Ordners an, in dem sich die Datei befindet.
Allow: /album/bild1.jpg
Disallow: /album/
- Sitemap
Der Befehl sitemap in robots.txt gibt den Pfad zur Sitemap an. Die Direktive kann weggelassen werden, wenn die Sitemap einen Standardnamen hat, sich im Stammverzeichnis befindet und über den Link “site name”/sitemap.xml zugänglich ist, ähnlich wie die Datei robots.txt.
Beispiel
Inhaltsverzeichnis: https://website.com/sitemap2020.xml
- Crawl-delayy
Um eine Überlastung des Servers zu vermeiden, kannst Du den Suchrobotern die empfohlene Anzahl von Sekunden für die Verarbeitung einer Seite mitteilen. Heutzutage durchforsten die Suchmaschinen die Seiten jedoch mit einer Verzögerung von 1 oder 2 Sekunden. Es sollte betont werden, dass diese Richtlinie für Google nicht mehr relevant ist.
Beispiel
User-agent: Bing
Crawl-dealy: 2
Wann sollte der Robots-Meta-Tag verwendet werden?
Wenn Du den Inhalt einer Website vor den Suchergebnissen verbergen willst, reicht die Datei robots.txt nicht aus. Robots werden mit Hilfe des Robots-Meta-Tags, das der <head>-Überschrift des HTML-Codes einer Seite hinzugefügt wird, angewiesen, Seiten nicht zu indizieren. Die noindex-Direktive zeigt an, dass der Seiteninhalt nicht indiziert werden kann. Eine andere Möglichkeit, die Indizierung einer Seite einzuschränken, besteht darin, ihre URL im X-Robots-Tag der Konfigurationsdatei der Website anzugeben.
Beispiel für das Schließen auf Seitenebene
<head> <meta name="robots" content="noindex"> </head>
Welche Arten von Suchcrawlern gibt es?
Ein Such-Crawler ist eine spezielle Art von Programm, das Webseiten scannt und sie in die Datenbank einer Suchmaschine einträgt. Google hat mehrere Bots, die für verschiedene Arten von Inhalten zuständig sind.
- Googlebot: crawlt Websites für Desktop- und Mobilgeräte
- Googlebot Image: zeigt Bilder der Website im Abschnitt “Bilder” an
- Googlebot Video: scannt und zeigt Videos an
- Googlebot News: wählt die nützlichsten und hochwertigsten Artikel für die Rubrik “News” aus
- Adsense: Einstufung einer Website als Anzeigenplattform in Bezug auf die Relevanz der Anzeigen
Die vollständige Liste der Google-Robots (User Agents) ist in der offiziellen Hilfedokumentation aufgeführt.
Die folgenden Roboter sind für andere Suchmaschinen relevant: Bingbot für Bing, Slurp für Yahoo!, Baiduspider für Baidu, und die Liste ist damit noch nicht zu Ende. Es gibt über 300 verschiedene Suchmaschinen-Bots.
Neben Suchrobotern kann die Website auch von Crawlern analytischer Ressourcen wie Ahrefs oder Screaming Frog gecrawlt werden. Die Arbeit ihrer Softwarelösungen basiert auf demselben Prinzip wie die von Suchmaschinen: Sie analysieren URLs, um sie in ihre eigene Datenbank aufzunehmen.
Bots, die für den Zugriff auf Websites gesperrt werden sollten:
- Bösartige Parser (Spambots, die E-Mail-Adressen von Kunden sammeln, Viren, DoS- und DDoS-Angriffe und andere);
- Bots anderer Unternehmen, die Informationen überwachen, um sie für ihre eigenen Zwecke weiterzuverwenden (Preise, Inhalte, SEO-Methoden usw.).
Wenn Du beschließt, die Website vor den oben genannten Robotern zu sperren, ist es besser, die .htaccess-Datei anstelle der robots.txt zu verwenden. Die zweite Methode ist sicherer, da sie den Zugang nicht als Empfehlung, sondern auf Serverebene einschränkt.
SetEnvIfNoCase User-Agent “Bot-Name-1” search_bot
SetEnvIfNoCase User-Agent “bot name-2” search_bot
Der Befehl muss am Ende der .htaccess-Datei angegeben werden. Die Scan-Einschränkungen für jeden Roboter müssen in einer eigenen Zeile angegeben werden.
Beispiel für robots.txt-Inhalt
Eine Dateivorlage mit aktuellen Direktiven hilft dir, die robots.txt-Datei richtig zu erstellen, indem sie die erforderlichen Robots angibt und den Zugriff auf die relevanten Site-Dateien einschränkt.
User-agent: [Bot-Name]
Disallow: /[Pfad zu Datei oder Ordner]/
Disallow: /[Pfad zu Datei oder Ordner]/
Disallow: /[Pfad zu Datei oder Ordner]/
Sitemap: [Sitemap URL]
Sehen wir uns nun einige Beispiele dafür an, wie die robots.txt-Datei auf verschiedenen Websites aussieht.
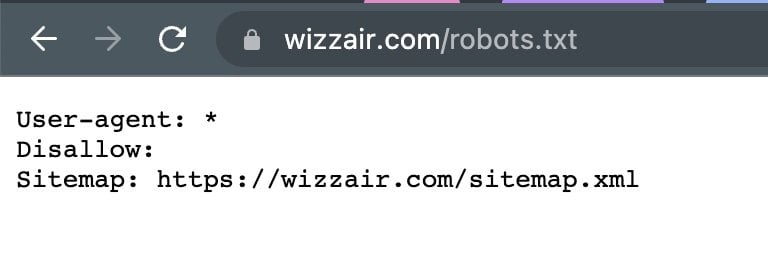
Hier ist eine minimalistische Version:
Im folgenden Beispiel sehen wir eine Liste von Website-Verzeichnissen, die für das Scannen gesperrt sind. Für einige Bots wurden separate Gruppen erstellt, die das Crawlen der Website generell verbieten (Yandex, niki-bot):
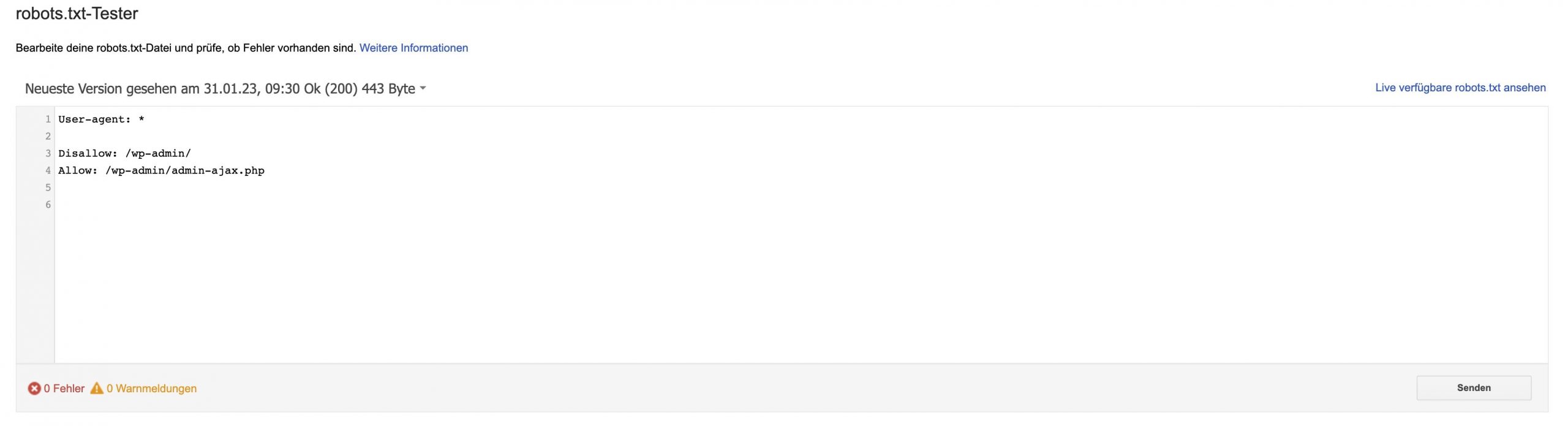
Wie Du deine robots.txt-Datei überprüfst
Manchmal können Fehler in der robots.txt-Datei nicht nur dazu führen, dass wichtige Seiten aus dem Index ausgeschlossen werden, sondern auch dazu, dass die gesamte Website für Suchmaschinen praktisch unsichtbar wird.

Die Option zur Überprüfung der robots.txt-Datei fehlt in der neuen Oberfläche der Google Search Console. Jetzt kannst Du die Indizierung von Seiten einzeln überprüfen (URL überprüfen) oder Anfragen zum Löschen von URLs senden (Index – Entfernungen). Das Robots.txt Tester kann direkt aufgerufen werden.
Wie kann robots.txt sonst noch verwendet werden?
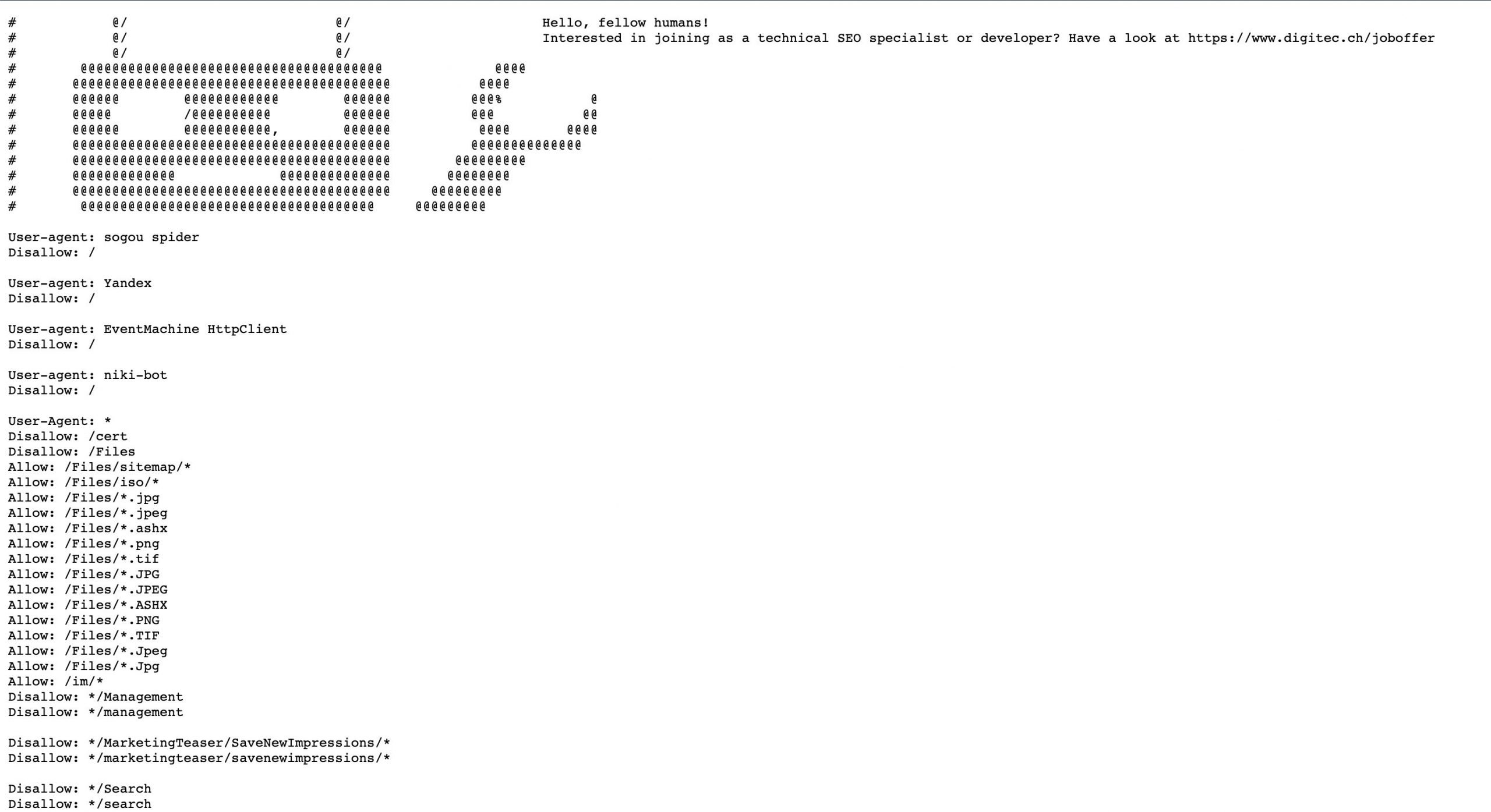
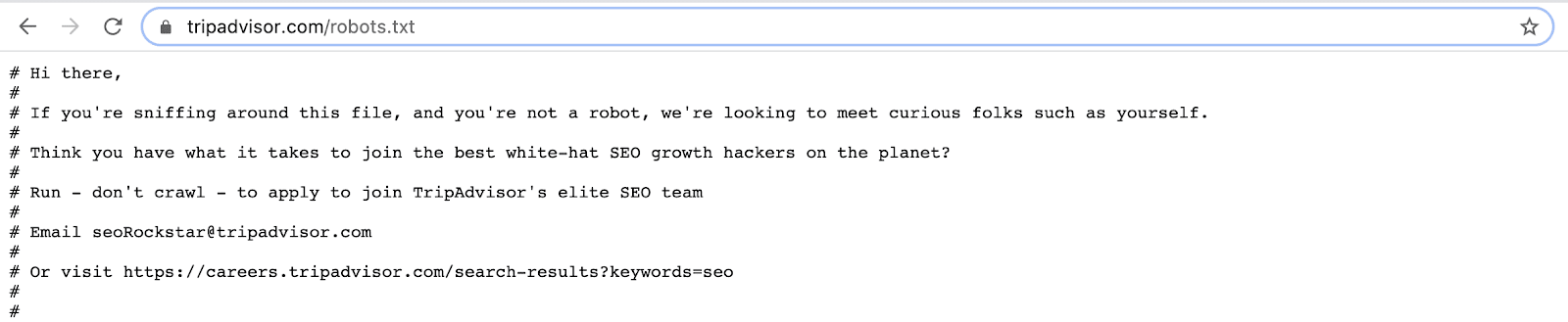
Der Inhalt der robots.txt-Datei kann mehr als nur eine Liste von Richtlinien für Suchmaschinen enthalten. Da die Datei öffentlich zugänglich ist, sind einige Unternehmen bei der Erstellung kreativ und humorvoll. Manchmal findet man ein Bild, ein Markenlogo und sogar ein Stellenangebot. Eine benutzerdefinierte robots.txt-Datei wird mit Hilfe von #-Kommentaren und anderen Symbolen erstellt.
Diese Angaben findest Du in der robots.txt-Datei von Digitec.ch:
Nutzer, die sich für die robots.txt einer Website interessieren, sind höchstwahrscheinlich gut in der Optimierung. Daher kann das Dokument eine zusätzliche Möglichkeit sein, SEO-Spezialisten zu finden.
Und das ist, was Du auf TripAdvisor findest:
Und hier ist ein kleines Doodle, das auf der Website des Esty-Marktplatzes hinzugefügt wurde:

Schlussfolgerungen
Im Folgenden findest Du einige wichtige Erkenntnisse aus diesem Blogbeitrag, die Dir helfen werden, dein Wissen über robots.txt-Dateien zu festigen:
- Die robots.txt-Datei ist eine Richtlinie für Robots, die Dir sagt, welche Seiten gecrawlt werden sollen und welche nicht.
- Die robots.txt-Datei kann nicht so konfiguriert werden, dass sie die Indizierung verhindert, aber Du kannst die Wahrscheinlichkeit erhöhen, dass ein Roboter bestimmte Dokumente oder Dateien crawlt oder ignoriert.
- Das Ausblenden nicht hilfreicher Website-Inhalte mit der disallow-Direktive spart das Crawl-Budget. Dies gilt sowohl für mehrseitige als auch für kleine Websites.
- Ein einfacher Texteditor reicht aus, um eine robots.txt-Datei zu erstellen, und die Google Search Console reicht aus, um eine Überprüfung durchzuführen.
- Der Name der robots.txt-Datei muss in Kleinbuchstaben geschrieben sein und darf 500 KB nicht überschreiten.
Wenn Du Fragen oder Anregungen hast, schreib uns bitte in die Kommentare!

